Beta. Benchmarks is a beta feature and may change.
When to use a benchmark instead of a simulation
A simulation runs a full, multi-turn conversation against your agent to see how it behaves end to end. A benchmark is narrower: it’s a quick, single-turn test that runs one input (a piece of audio or text) through each provider and measures accuracy and latency. Use a benchmark when you just want to compare STT or TTS providers in isolation — picking a transcription or voice model — without setting up an agent, personas, or a full conversation.What each measures
| STT | TTS | |
|---|---|---|
| You provide | Audio files (with reference transcripts) | Text prompts |
| Primary metric | Word Error Rate (WER) — lower is more accurate | Time to First Audio (TTFA) — lower is faster |
| Also measured | P95 WER, average and P95 latency | P50/P95 TTFA, total latency, audio duration |
Running a benchmark
Each page has four tabs: Results, Past Runs, Datasets, and Custom Endpoints.Pick a dataset
The input every provider runs on — audio files for STT, text prompts for TTS. Use a built-in Coval template or create your own under Datasets.
Choose providers
Select from Coval’s catalog (Deepgram, OpenAI, AssemblyAI, ElevenLabs, Google, Azure, Amazon, and more) or add your own provider, model, and API key under Custom Endpoints.
Reading the results
The Results tab compares providers across runs: line charts for WER and latency over time, and a per-model heatmap for the latest run (green best, red worst) you can sort by any column. Filter by dataset or model, open a run for the per-item breakdown, and click a result to compare the reference against the provider’s output.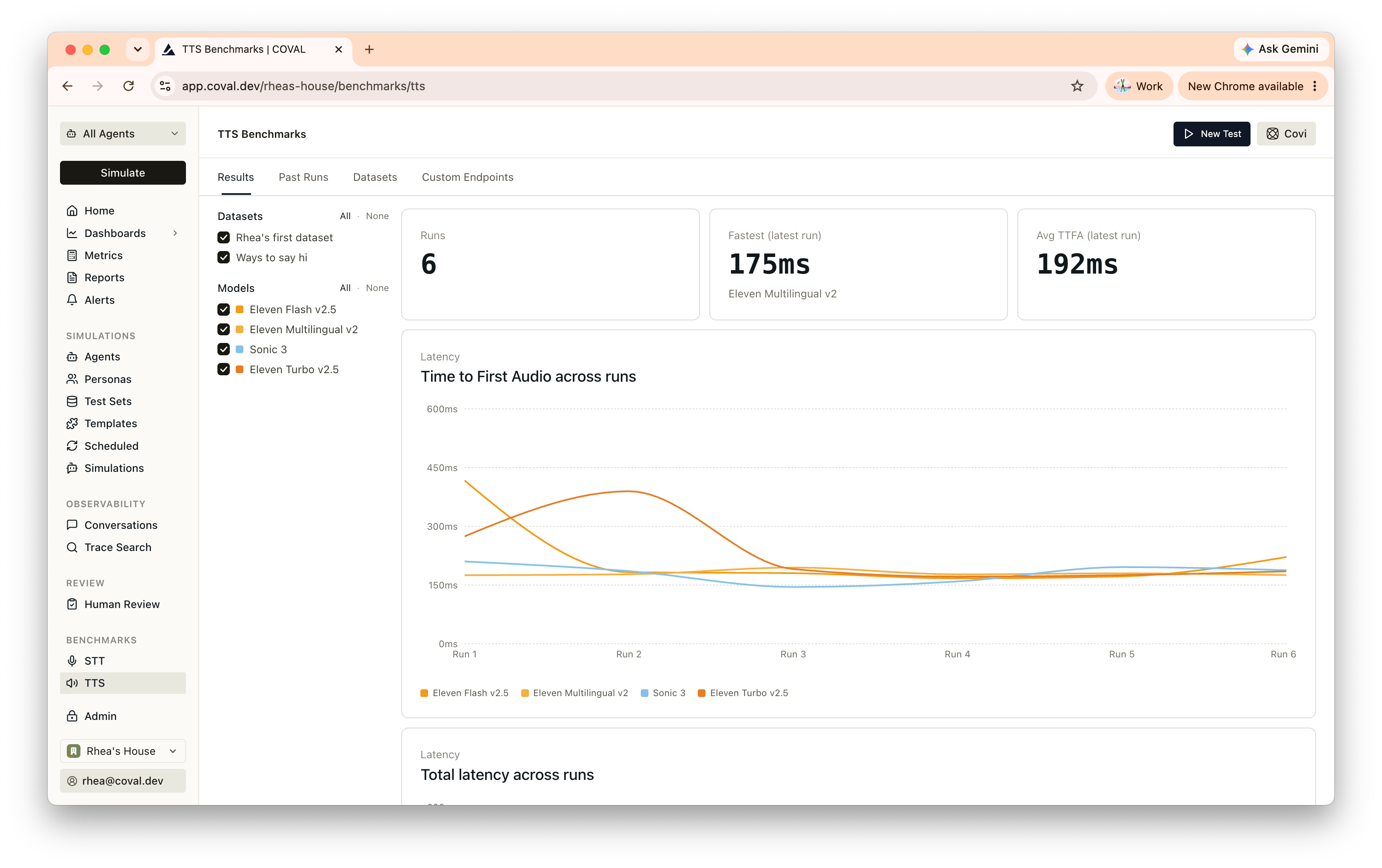
Limits
Limits
| Limit | |
|---|---|
| Audio file size | 10 MB |
| Audio duration | 300 seconds |
| TTS text length | 2,000 characters |
| Items per dataset | 200 |
| Providers per run | 10 |
| Concurrent requests | 10 |